卷积神经网络为什么认不出我写的数字?
本文最后更新于:几秒前
卷积神经网络为什么认不出我写的数字?

在MNIST上训练
MNIST是一个经典的手写体数字数据集,包含了7万个手写数字,这些数字是从0到9的任何整数。我们将用这个数据集训练我们的视觉模型。其中的部分数据如下: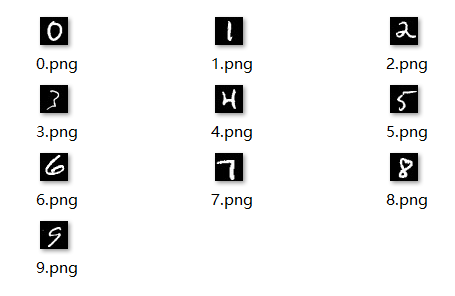
生活中的手写数字往往是偏白色背景,黑色字体的,所以我们根据源数据,将图片的颜色翻转,得到下面的数据集(部分数据):
我们再把这两个数据集结合起来,作为最终的手写体数据集(14万个手写数字)来训练我们的模型。其中80%的数字用于训练,另外20%的数字用于验证(不参与训练)。
我们的模型的结构:
1 | |
inputs = keras.Input(shape=(28, 28, 3))- 定义输入层。这里的
shape=(28, 28, 3)表示输入图像的尺寸是28x28像素,并且有3个通道(RGB图像)。
- 定义输入层。这里的
layer1 = layers.Conv2D(filters=8, kernel_size=3, activation='relu')(inputs)- 定义第一个卷积层。
filters=8表示该层有8个卷积核(或过滤器)。kernel_size=3表示每个卷积核的大小是3x3。activation='relu'表示使用ReLU(Rectified Linear Unit)作为激活函数。
- 定义第一个卷积层。
layer2 = layers.MaxPooling2D(pool_size=2)(layer1)- 定义第一个最大池化层。
pool_size=2表示池化窗口的大小是2x2。这有助于降低图像的空间维度。
- 定义第一个最大池化层。
layer3 = layers.Conv2D(filters=16, kernel_size=3, activation='relu')(layer2)- 定义第二个卷积层,该层有16个卷积核。
layer4 = layers.MaxPooling2D(pool_size=2)(layer3)- 定义第二个最大池化层。
layer5 = layers.Conv2D(filters=32, kernel_size=3, activation='relu')(layer4)- 定义第三个卷积层,该层有32个卷积核。
layer6 = layers.Flatten()(layer5)- 将卷积层的输出展平,以便可以连接到全连接层。
layer7 = layers.Dense(128, activation='relu')(layer6)- 定义一个全连接层,有128个节点,并使用ReLU作为激活函数。
outputs = layers.Dense(10, activation='softmax')(layer6)- 定义输出层,有10个节点(对应于10个类别的分类任务)。使用softmax激活函数,为每个类别(0~9)生成一个概率分布。
model = keras.Model(inputs=inputs, outputs=outputs, name='CNN')- 创建一个模型对象,指定输入和输出,并为模型命名为”CNN”。
训练过程:
数据集中80%的数字用于训练,另外20%的数字用于验证(不参与训练)。
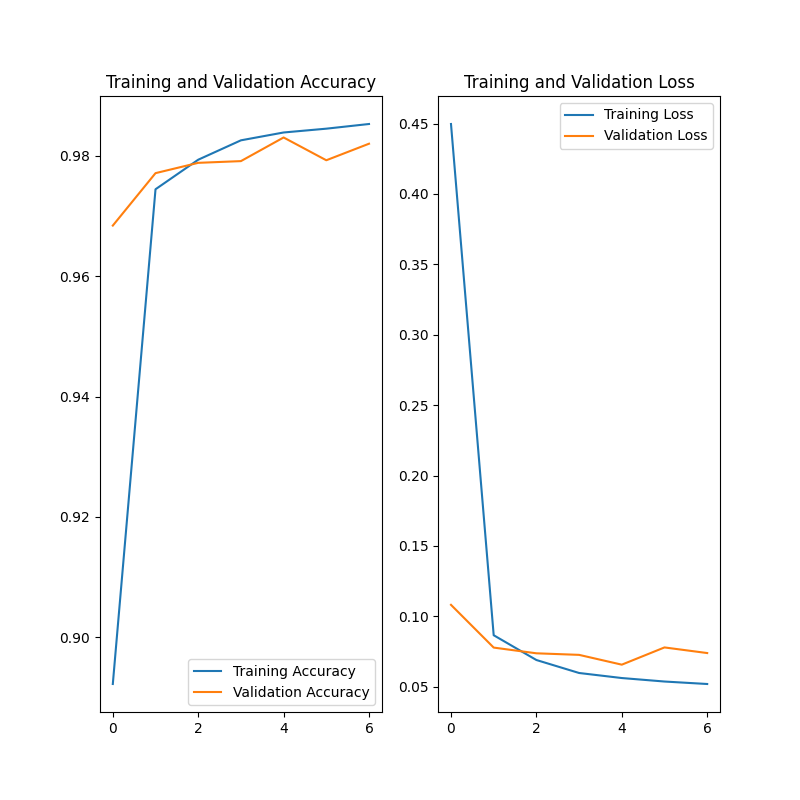
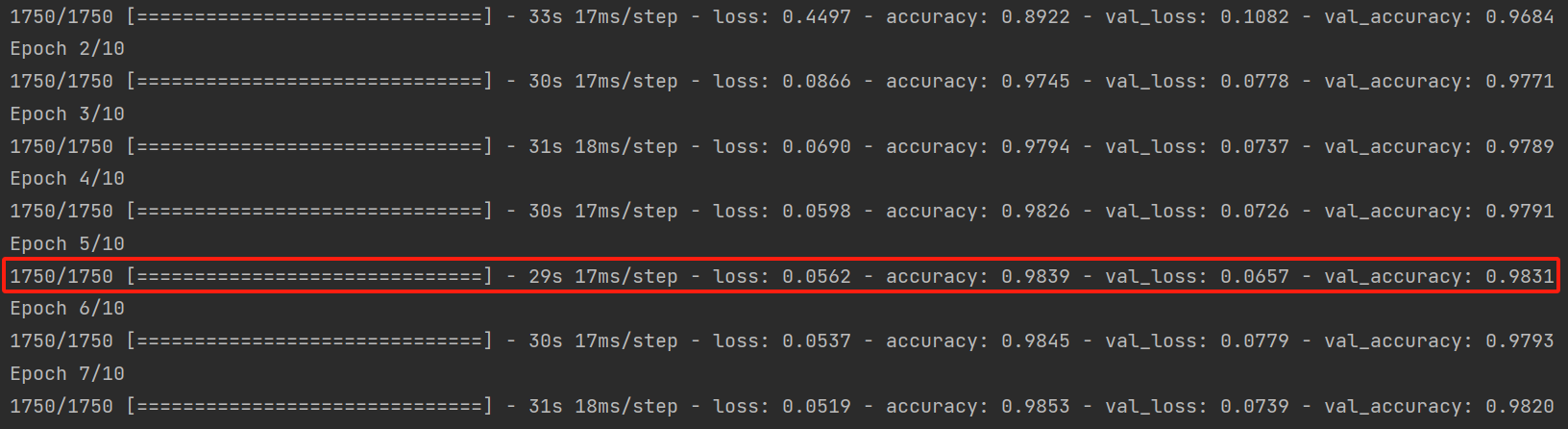
我们选择了第五轮训练后的模型作为最终模型,因为他的表现较好。
成功识别验证集中的数字
我们读取已经训练好的模型,并在验证集上进行预测。
1 | |
1 | |
效果还是挺好的,准确率达到了98%!即使没有预先看到过这些数字。
无法准确识别我写的数字
好的模型需要用到生活中去,躺在实验室里是没有意义的。所以我在A4纸上写下了0~9这10个数。

当然,只有这十个数字是不够做测试的,为了避免实验的偶然性,我又搜集了不同的人写的数字。这样我们的测试集就有50个数字了。
我们读取已经训练好的模型,并在这些数字上进行预测。
1 | |
1 | |
准确率只有76%,这相比于98%还是差了很多的。损失值更是达到了0.866,是在验证集上的13倍!
问题原因
同样是卷积网络未曾见过的数字,为什么准确率差这么多?

难道是因为我写的“6”的背景不够白吗?对于我们(人)而言,可以通过他们之间的色差区分出图中的数字。显然这个实验中的卷积网络不是根据这个特征来识别数字的。难道他过拟合了,认为只有纯白和纯黑组合成的图片才更有可能是数字?
解决办法
我们可以通过增加卷积核的方法来提升卷积网络学习特征的能力,并通过添加“dropout”层来阻止网络过度依赖某一特征,从而防止过拟合。
改进后的模型的结构:
1 | |
inputs = keras.Input(shape=(28, 28, 3))- 这行代码定义了模型的输入层。
shape=(28, 28, 3)表示输入的图像是一个28x28像素的RGB图像(因此总共有3个通道)。
- 这行代码定义了模型的输入层。
layer1 = layers.Conv2D(filters=32, kernel_size=3, activation='relu')(inputs)- 创建一个二维卷积层,包含32个过滤器(或称为卷积核),每个过滤器的大小为3x3。
activation='relu'表示使用ReLU(Rectified Linear Unit)作为激活函数。
- 创建一个二维卷积层,包含32个过滤器(或称为卷积核),每个过滤器的大小为3x3。
layer1_drop = layers.Dropout(0.15)(layer1)- 在
layer1上添加一个dropout层,dropout率(即随机忽略的神经元比例)为0.15。
- 在
layer2 = layers.MaxPooling2D(pool_size=2)(layer1_drop)- 添加一个最大池化层,池化窗口的大小为2x2。
layer3 = layers.Conv2D(filters=64, kernel_size=3, activation='relu')(layer2)- 创建另一个卷积层,这次包含64个过滤器。
layer3_drop = layers.Dropout(0.18)(layer3)- 在
layer3上添加另一个dropout层,这次dropout率为0.18。
- 在
layer4 = layers.MaxPooling2D(pool_size=2)(layer3_drop)- 再添加一个最大池化层。
layer5 = layers.Conv2D(filters=64, kernel_size=3, activation='relu')(layer4)- 再次创建卷积层,包含64个过滤器。
layer5_drop = layers.Dropout(0.20)(layer5)- 在
layer5上添加另一个dropout层,这次dropout率为0.20。
- 在
layer6 = layers.Flatten()(layer5_drop)- 将
layer5_drop的输出展平,这样它可以从一个多维张量转换为一个一维张量,以便可以连接到全连接层。
- 将
layer7 = layers.Dense(128, activation='relu')(layer6)- 创建一个全连接层(也称为密集层),包含128个神经元,并使用ReLU作为激活函数。
layer7_drop = layers.Dropout(0.15)(layer7)- 在
layer7上添加一个dropout层,dropout率为0.15。
- 在
outputs = layers.Dense(10, activation='softmax')(layer7_drop)- 创建一个输出层,包含10个神经元(对应于0~9这十个类别),并使用softmax激活函数进行分类。
model = keras.Model(inputs=inputs, outputs=outputs, name='CNN')- 创建一个模型对象,将输入和输出连接起来,并命名为“CNN”。
训练过程:
数据集中80%的数字用于训练,另外20%的数字用于验证(不参与训练)。
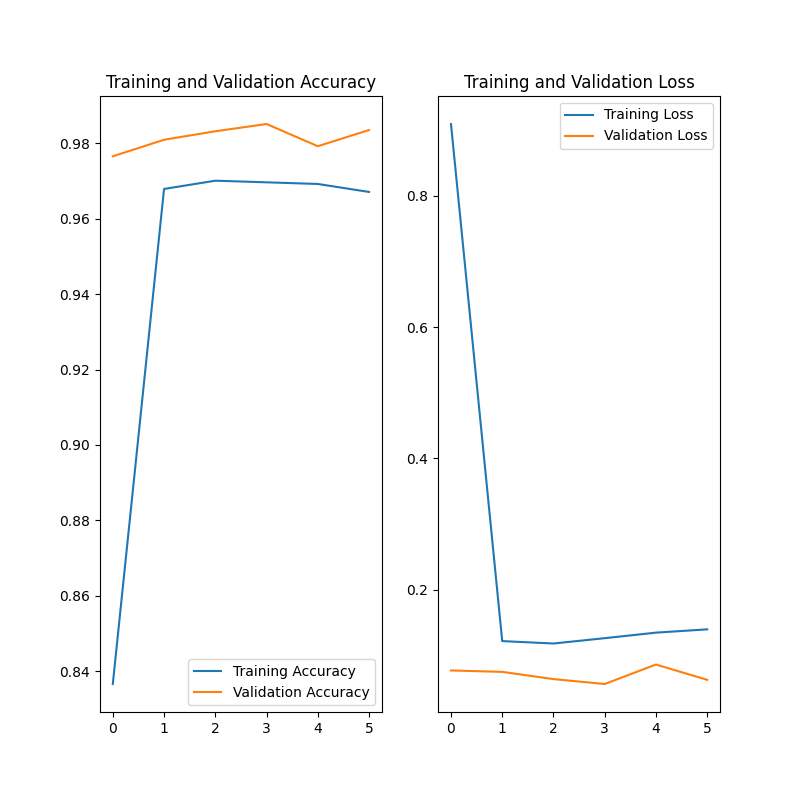
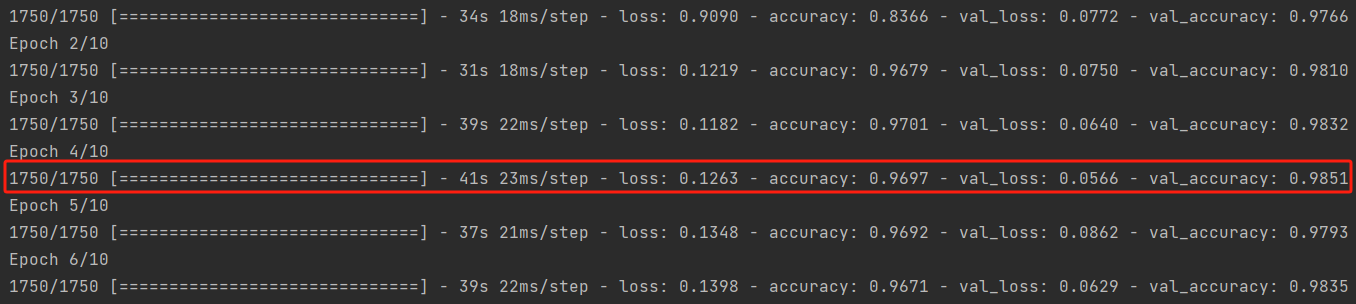
这次我们选择了第四轮训练后的模型作为最终模型,因为他的表现较好。
预测生活中的数字
我们读取已经训练好的模型,并在数据集上进行预测。
1 | |
1 | |
精度和损失值都有明显的提升,这并不是偶然事件。事实上,我已经在相同的架构上训练了好几次了(改进前和改进后)。最后的结果都表明改进后的模型具有较好的泛化能力。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!