信息复习笔记-数据处理基础
本文最后更新于:1 年前
这次我们复习数据处理。
本文用到的Excel数据如下,后续不再说明。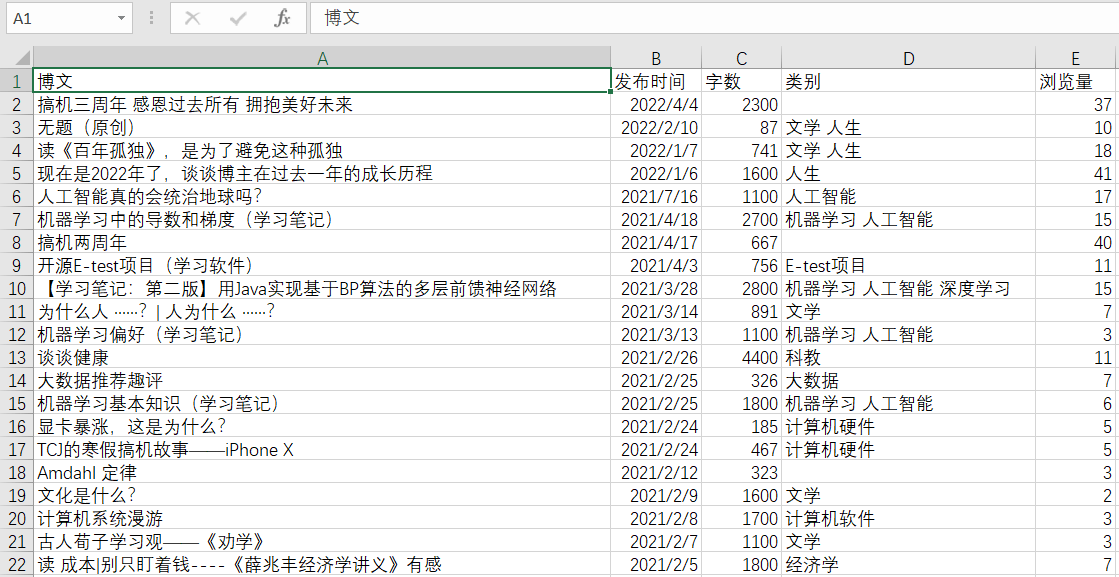
一、常用的数据处理和统计分析工具
常用的数据处理和统计分析工具有 Excel、SPSS、SAS、MATLAB 等软件,也可以通过 R、Python、Java 等计算机语言编程进行数据处理。本笔记将会复习怎么用 Excel 和 Python 处理数据。
二、使用 Excel 软件进行数据计算的一般步骤
分析表格数据→抽象计算模型→计算→分析计算结果→描述其含义。
三、数据计算
在 Excel 软件中,主要有自定义公式和函数两种方式。
①自定义公式:公式是以“=”开头,由常数、函数、单元格引用和运算符(如+、-、*、/、%、^等)组成的式子。
②函数:函数是预定义的公式,通过使用参数按特定顺序或结构进行计算。常用函数有 SUM(数据区域)、AVERAGE(数据区域)、MIN(数据区域) 和 MAX(函数区域) 等。
解析:计算博文的总字数:任取一单元格并输入公式即可


注意:函数计算时会自动忽略非数字类型单元格;单元格引用:连续的区域用冒号连接来表示,不连续的区域用逗号进行分隔。
| 类型 | 书写格式 | 举例 |
|---|---|---|
| 连续区域 | 区域左上角单元格和区域右下角单元格,通过冒号连接 | A8:C19 |
| 不连续区域 | 将不连续的区域通过逗号隔开 | A8:C19,E8,E19 |
四、数据排序
①数据排序分为单个关键字排序和多个关键字排序。
②排序时选择的数据区域必须是连续的。
③排序时根据条件选择有标题行或无标题行排序。
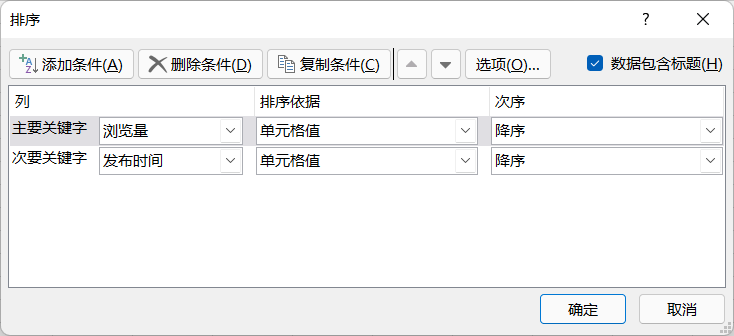
解析:多个关键字排序,这里的数据有标题,所以在排序时选择数据包含标题,Excel 会自动忽略标题而只对数据进行排序。
排序结果如下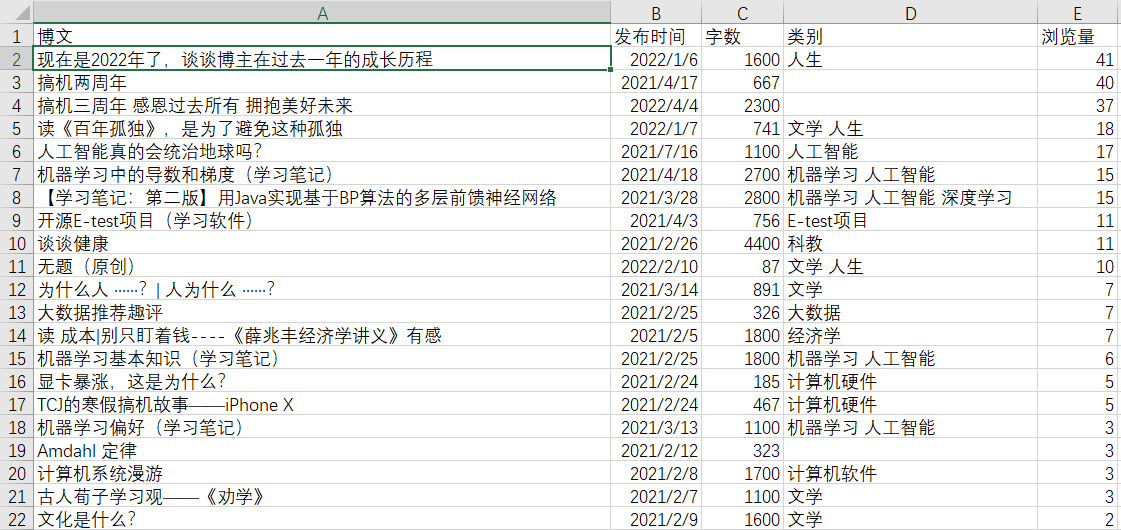
注意:1.排序区域的选取原则:①只能选择一个连续区域。②避开合并单元格。③一般不能只选单列。
2.主要关键字和次要关键字的区别:①主要关键字相同才看次要关键字。②主要关键字只有一个,次要关键字可以有多个。③排序可以按列排序,也可以按行排序。④汉字可以按拼音(第一个字首字母)排序,也可以按笔画(第一个字)排序。
五、数据筛选(自动筛选)
筛选后的表格中显示满足条件的数据,其他数据被隐藏,筛选的范围是表格中的所有数据。数据筛选的主要方式有:①自定义筛选。②10个最大(小)的值,单位可以是项或者百分比。③多条件筛选。
解析:筛选就是要从数据中选出满足一定条件的部分数据,可以筛选一个或多个数据列。筛选只是将不符合条件的数据隐藏,而不是删除数据。在某一列上执行筛选之后,还可以在另一列上再次执行筛选,这样,数据清单中只有同时满足两个不同的筛选条件的数据才能被显示出来。
我们尝试把未分类的博文隐藏。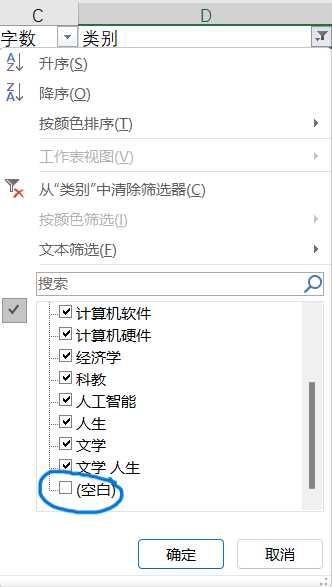
筛选结果
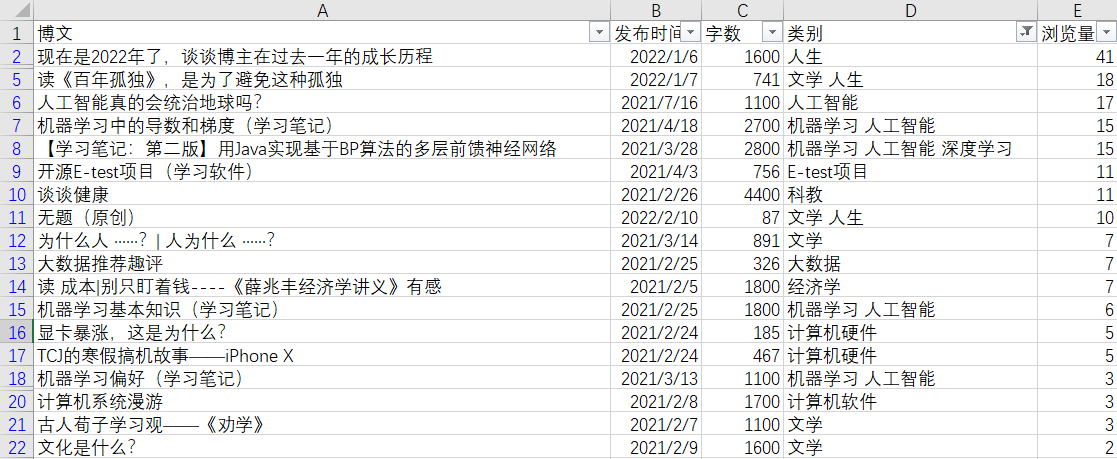
1.自定义筛选 选择“与”表示两个条件同时满足的数据才会显示,可以只选择一个条件
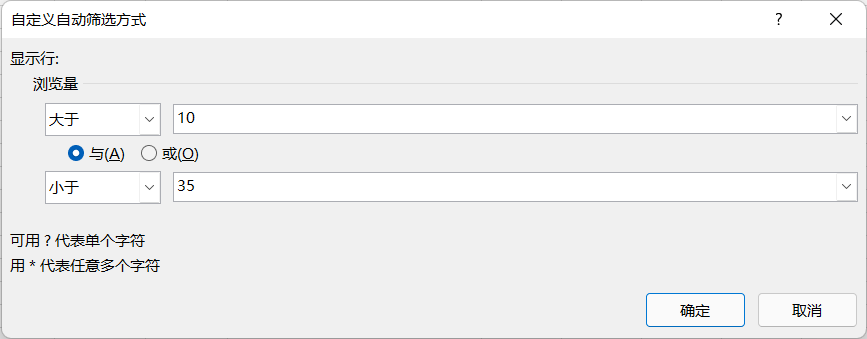
筛选结果

注意:①筛选选择区域时包含多行。②不能包含合并的单元格。③筛选区域必须是连续的。④一般情况下不选单个单元格,若选择单个单元格执行筛选,结果产生在A1单元格中。
2.“10个最大的项”(前十项) 可根据实际需要筛选“最大”或“最小”的前“n”项或百分比数据。如果有重复项导致数据超出“n”个,则会一并都显示出来。
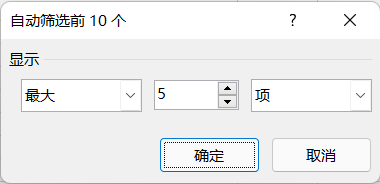
帅选结果

注意:①最大或者最小的1项或者多项。②若设置为百分比,当实际项数大于1时向下取整,当小于1时取1即可。
六、数据图表呈现
使用 Excel 软件创建图表呈现数据的一般步骤:分析表格数据→选择数据区域→插入图表→检查图表,描述数据特征。
常用的图表类型:柱形图、折线图、饼图、雷达图、散点图、气泡图、条形图等。
解析:数据源判断时,先看图例,再看横坐标的系列名。
注意:如果图表引用的数据区域发生变化(如数据修改、排序、筛选等操作),图表将会发生变化。但是设置小数位数不会影响图表和真实值。
七、行绝对引用和列绝对引用
如果不想让某个行号在自动填充时发生改变,则需要在行号前加绝对引用符号“$”,列同。
八、错误类型
| 错误类型 | 错误名称 | 错误原因 |
|---|---|---|
| #DIV/0! | 除零错误 | 除数为零 |
| #REF | 引用错误 | 删除(不是清除)了一个在公式中被引用的单元格 |
| #VALUE | 数据类型错误 | 比如一个文本型加一个数值型 |
| #NAME! | 函数名错误 | 如 SUM 拼成了 SUM |
| ######## | 不是错误,是列宽不够造成的 |
注意:“删除”是删除单元格本身,“清除”只是删除了单元格中可视的内容。
一、大数据处理的基本思想与架构
1.基本思想
处理大数据时,一般采用分治思想。
2.大数据处理类型
①静态数据:在处理时已收集完成、在计算时不会发生改变的数据,一般采用批处理方式。
②流数据:不间断地、持续地到达的实时数据,随着时间的流逝,流数据的价值也随之降低,通过实时分析计算可以得到更有价值的分析结果。
③图数据:现实世界中的许多数据,如社交网络、道路交通等数据,可采用图计算模式进行处理。
解析:三类数据对应的三种处理模式
1.批处理计算
①Hadoop 是一个可运行于大规模计算机集群上的分布式系统基础架构,适用于静态数据的批处理计算。Hadoop 计算平台主要包括 Common 公共库、分布式系统HDFS、分布式数据库 HBase、分布式并行计算模型 MapReduce 等多个模块。
②Spark 属于应用较广的开源分布式计算架构,Spark 启用了内存存储中间结果,运行速度比 Hadoop 快很多。
2.流计算
流计算主要用于处理流数据,比如大型购物网站的广告推荐、社交网络的个性化推荐等。处理流数据的软件系统主要有 Twitter Storm、Heron、Yahoo! S4等。Storm 和 S4 是目前较为流行的开源分布式实时计算系统。
3.图计算
①图数据库:Neo4j、InfiniteGraph、OrientDB 等。
②并行图处理系统:Google Pregel、Apache Giraph、卡内基梅隆大学的 GraphLab、运行于 Spark 平台的 GraphX 等。
二、使用Python处理数据
1.使用pandas模块处理数据 由于pandas模块是第三方库,所以需要提前下载到本地才能导入到项目中
pandas 提供了 Series 和 DataFrame 两种数据结构。使用这两种数据结构,可完成数据的整理、计算、统计、分析及简单可视化。
①Series
Series 是一种一维的数据结构,包含一个数组的数据和一个与数据关联的索引(index),索引值默认是从0起递增的整数。列表、字典等可以用来创建 Series 数据结构。
| Series对象属性 | 说明 |
|---|---|
| index | Series 的下标索引,其值默认是从0起递增的整数 |
| values | 存放 Series 值的一个数组 |
②DataFrame
DataFrame 是一种二维的数据结构,由1个索引列(index)和若干个数据列组成,每个数据列可以是不同的类型。DataFrame 可以看作是共享同一个 index 的 Series 的集合。
| DataFrame对象属性 | 说明 |
|---|---|
| index | DataFrame 的行索引 |
| values | 存放值的二维数据 |
| columns | 存放各列的列标题 |
| T | 行列转置 |
解析:1.Series 实践 先从清华大学的镜像源下载 pandas 模块到本地
1 | |
或者
1 | |
它们的输出结果都是
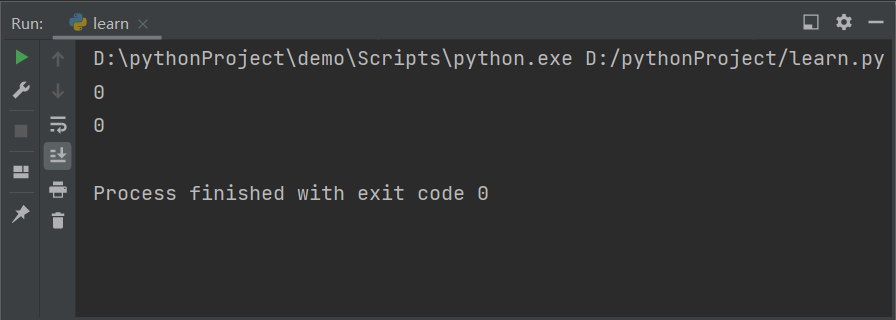
与列表和字符串不同的是,Series 还有布尔索引。
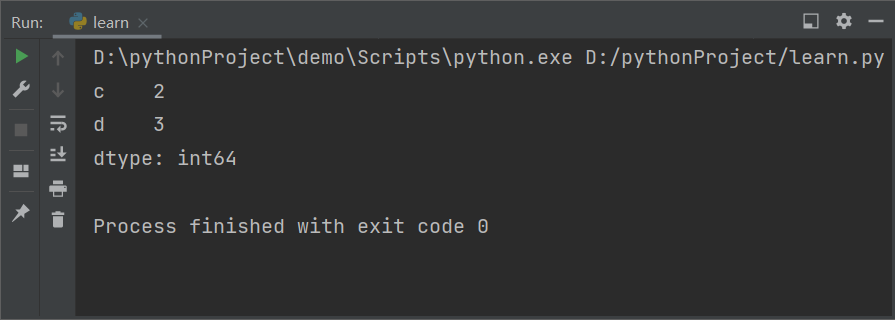
1 | |
控制台输出结果
2.DataFrame 实践
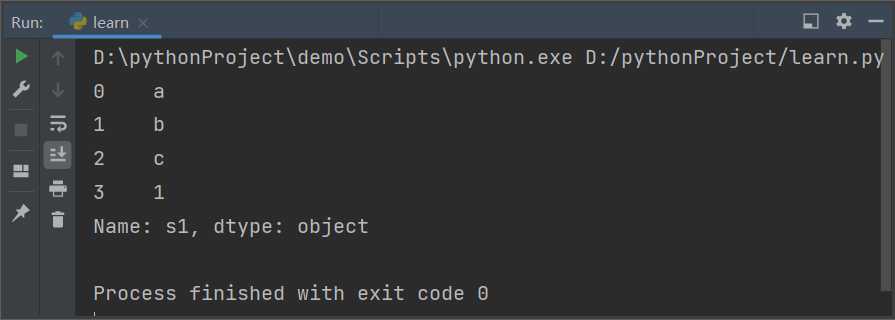
1 | |
控制台输出
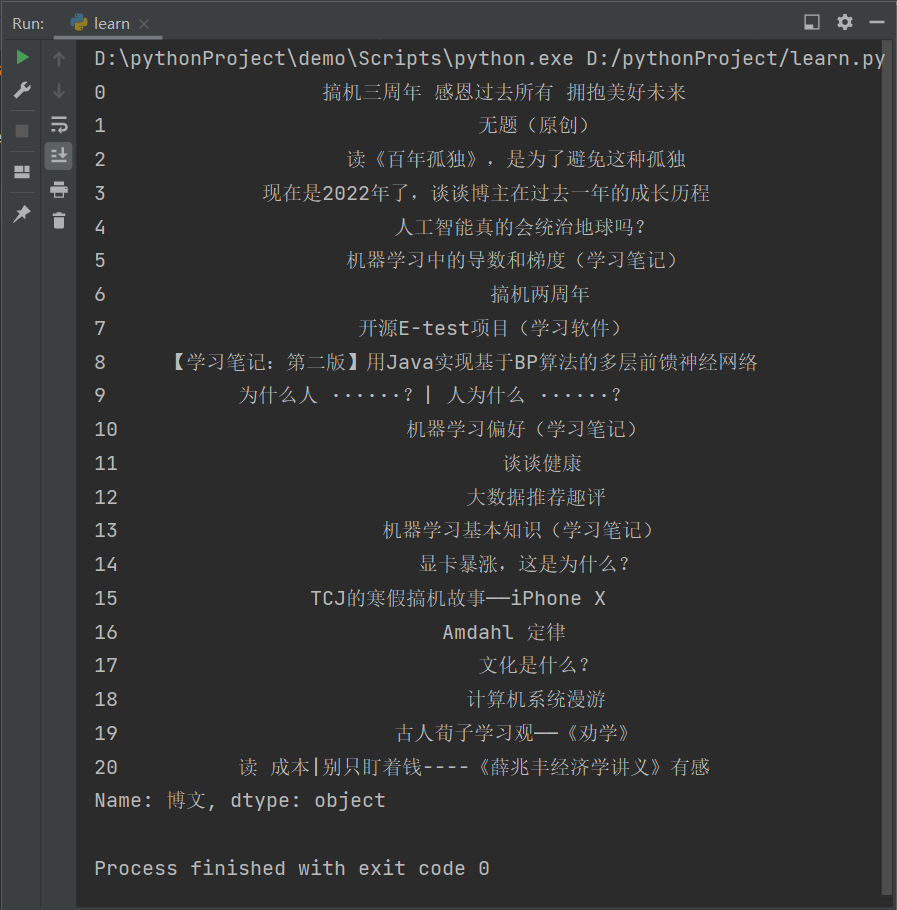
直接读取外部数据 读取excel文件需要 OpenPyXL 库,先下载

1 | |
控制台输出结果
读取CSV文件与上同。
python不仅能通过读取外部数据来创建DataFrame对象,还能将DataFrame对象的数据导出。以下操作实现了文件格式的转换。
1 | |
DataFrame 常用函数如下
| 函数 | 说明 |
|---|---|
| count() | 返回非空(NaN) 数据项的数量 |
| sum()、mean() | 求和、求平均值,通过 axis = 0/1 确定行列 |
| max()、min() | 返回最大、最小值 |
| describe() | 返回各列的基本描述统计值,包含计数、平均数、标准差、最大值、最小值及4分位差 |
| head()、tail() | 返回 DataFrame 的前 n 个,后 n 个数据记录 |
| groupby() | 对各列或各行中的数据进行分组,然后可对其中每一组数据进行不同的操作 |
| sort_values() | 排序,通过 axis = 0/1 确定行列 |
| drop() | 删除数据,通过 axis = 0/1 确定行列 |
| append() | 在指定元素的结尾插入内容 |
| insert() | 在指定位置插入列 |
| set_value() | 根据行标签和列标签设置单个值 |
| rename() | 修改列名或者索引 |
| contact() | 合并 DataFrame 对象 |
| plot() | 绘图 |
实践
1 | |
控制台输出结果
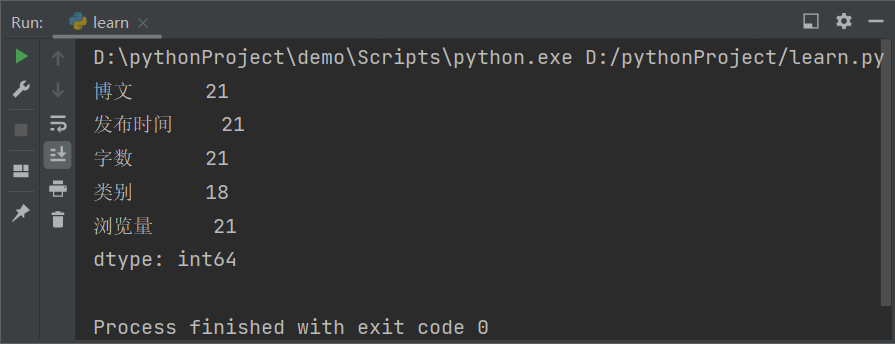
由此可以知道未指定类别的博文数量。
1 | |
控制台输出结果
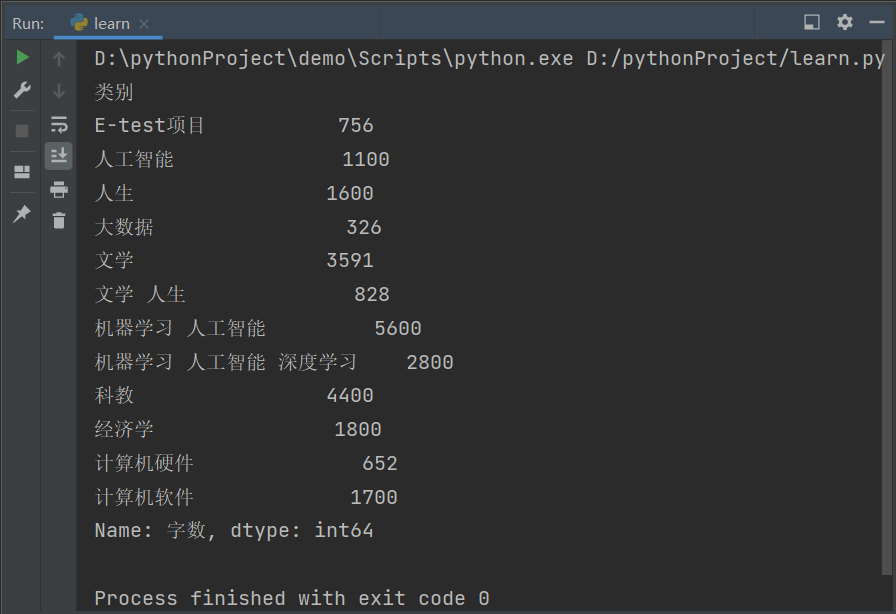
2.使用 matplotlib 模块使数据可视化 由于matplotlip模块是第三方库,所以需要提前下载到本地才能导入到项目中
matplotlib 常用函数
| 函数 | 说明 |
|---|---|
| figure() | 创建一个新的图表对象,若直接调用绘图函数,则matplotlib会自动创建 figure 对象 |
| plot() | 绘制线形图 |
| bar() | 绘制垂直柱形图 |
| barh() | 绘制水平柱形图 |
| scatter() | 绘制散点图 |
| title() | 设置图表的标题 |
| xlim()、ylim() | 设置X、Y轴的取值范围 |
| xlabel()、ylabel() | 设置X、Y轴的标签 |
| legend() | 显示图例 |
| show() | 显示创建的所有绘图对象 |
实践
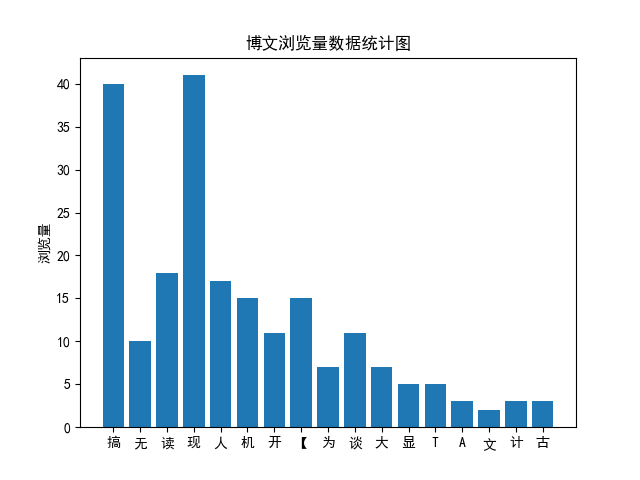
1 | |
结果 由于博文名的第一个字有重复,所以 plt 会自动忽略重复值
— 【参考资料 —— 《五三》和 网络文献】
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!